
Most companies, when they think about a knowledge base, still picture getting information into one place.
Policies, slide decks, FAQs, training materials, project retrospectives, contract templates — pull everything into a system, connect an AI question-and-answer interface.
It looks like knowledge management is complete.
What has actually happened is a file migration.
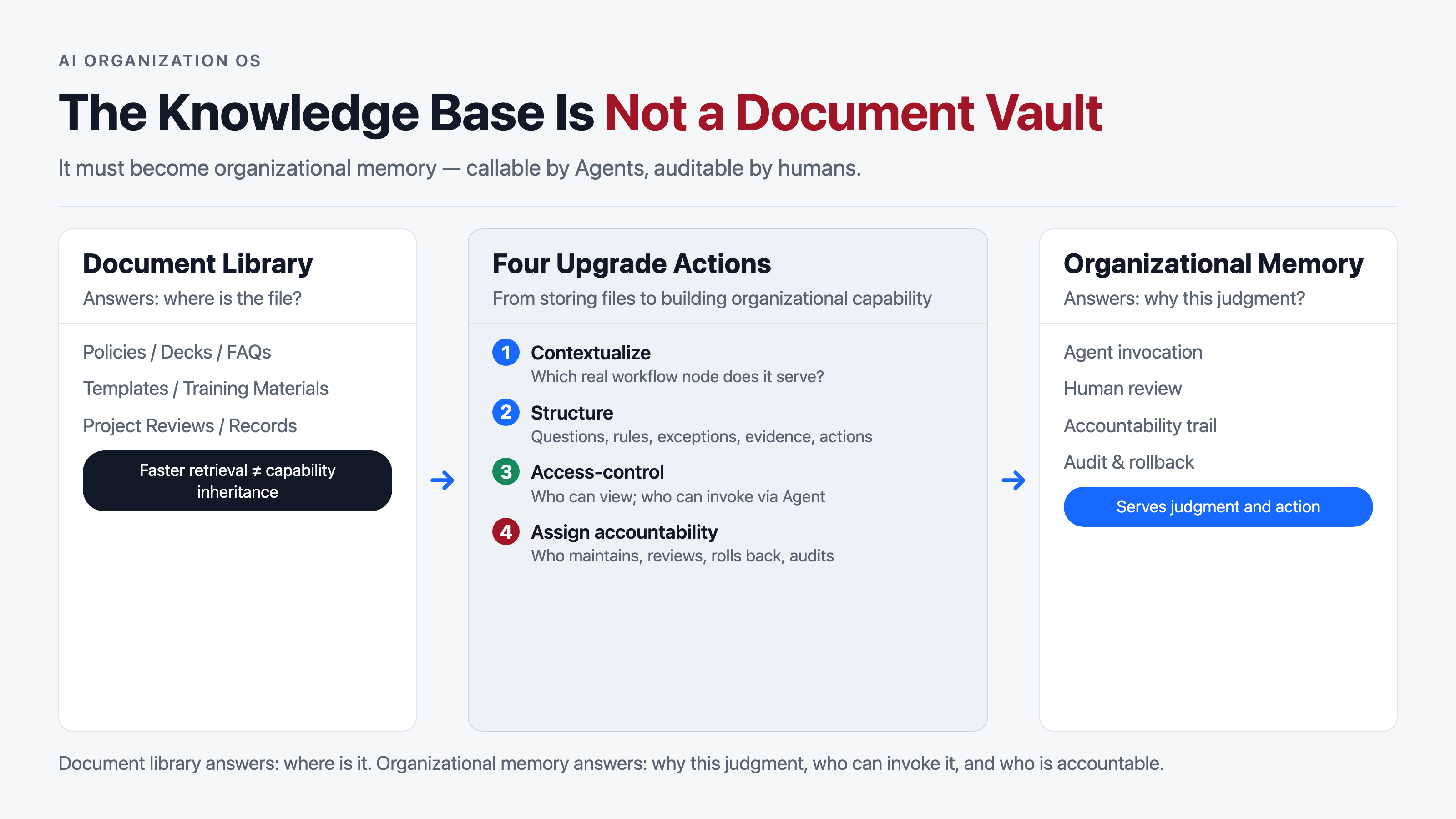
A document library answers: where is the material?
Organizational memory answers: why does this organization make the judgments it makes, under what conditions can those judgments be reused, who has the authority to access them, who is responsible for keeping them current, and when something goes wrong, who can trace back to the source?
These are not the same layer of problem.
If all you do is feed documents to AI, the best outcome is a more convenient retrieval interface. Employees spend less time flipping through files, customer service finds standard answers faster, sales grabs product talking points more efficiently.
All of that is useful.
But the things an organization's weight actually rests on are usually not in the documents.
Why was this exception handled this way?
Why can we not make that kind of commitment to this particular client?
Why does this process require an extra review step?
Why does that long-tenured employee spot a problem in this request the moment they see it?
Until those things are extracted from people's heads, AI can read the materials. It cannot inherit the judgment.
I. Materials, Experience, Organizational Memory — These Are Not the Same Thing
Every enterprise has at least three layers of knowledge.
The first layer is materials.
Materials are documents, policies, slide decks, SOPs, FAQs, product documentation, contract templates. They are storable, copyable, searchable. Their problem is also obvious: too many, scattered, outdated, duplicated, and maintained by nobody.
AI can help people find materials faster. But materials do not automatically become judgment.
The second layer is experience.
Experience is project retrospectives, expert judgment calls, unwritten rules, documented mistakes, client preferences, vendor quirks, the hands-on intuition of long-tenured employees. It does not always make it into documents. Much of it lives in people's heads, in chat logs, in meeting notes, in on-the-spot decisions.
Experience is closer to real work than materials are.
But it is hard to transfer, hard to hand off, hard to audit.
The third layer is organizational memory.
Organizational memory is not simply piling up materials and experience. It is structuring reusable judgment criteria, workflow rules, exception conditions, accountability records, and retrospective conclusions — so that both people and agents can access them under the right permission levels.
It has to answer at least five questions:
- Where did this piece of knowledge come from?
- Which scenarios does it apply to?
- Who can access it?
- When does it expire?
- Who fixes it when it is wrong?
Leave out any one of those questions and organizational memory reverts to a document library.
The problem in many organizations today is that materials are plentiful, experience is plentiful, but organizational memory is scarce. New employees still get brought up to speed by sitting next to someone. Cross-department coordination still runs on who-do-you-know. After AI is plugged in, all the system can do is search through documents — it cannot find the organization's actual judgment logic.
This is why a knowledge base is not something IT can build alone.
IT manages the system.
The business has to contribute the scenarios.
Leadership has to define the accountabilities.
The organization has to decide which experience is worth converting into memory.
II. The AI Productivity Paradox: Individuals Speed Up, the Organization Does Not Necessarily Get Stronger
In May 2026, Sequoia Capital published a recap of AI Ascent 2026: the fourth edition of the event took place on April 20 in San Francisco, bringing together over 150 AI founders and researchers. The piece noted that Sonya Huang described 2026 as the year of agents, and that the on-site agenda included long-horizon agents as a major theme.[^1]
The signal is clear: agents are moving from capability demonstration into longer-horizon execution in the real world.
But inside enterprises, there is another, quieter problem.
Individuals speed up first. The organization does not automatically get stronger.
Employees use Cursor to write code, Claude to draft documents, NotebookLM for research, and various other tools to process information. Each person has acquired a new set of capabilities bolted on.
The problem: the context, prompts, correction logs, and judgment paths those tools generate largely stay in individual accounts, on individual machines, and inside individual work habits.
When an employee leaves, that memory walks out with them.
When a tool is upgraded, that memory can reset to zero.
When work crosses people, that memory is difficult to transfer legally, accurately, and with low friction.
Some observers have called this phenomenon the "AI productivity paradox": each individual gets faster, but organizational capability does not automatically compound. The framing is a useful field observation, not an established academic definition from a single source. The underlying point is accurate: AI has loaded efficiency onto individuals first, but the organizational OS has not converted those individual gains into company-level capability.
Each employee is like a small factory that gained new equipment.
But the factories have no roads connecting them.
No roads means no organizational memory. No organizational memory means no inheritable capability.
When leaders look at AI transformation, they cannot stop at "are employees using the tools?" That only measures individual add-on adoption.
What actually matters: which judgments have been retained in the system, which experiences can now be handed off, which knowledge can be accessed by agents and also audited by humans.
Without that, individual productivity is loud and visible.
Company capability has not actually come online.
III. Upgrading a Document Library to Organizational Memory Requires Four Moves
Upgrading a document library to organizational memory cannot start with "what material should we upload?"
It must start with real scenarios.
The first move is contextualization.
Ask first: which actual work scenario does this knowledge serve? Is it customer service Q&A, contract review, sales pricing, engineering review, or post-sale fault handling?
Without a scenario, knowledge becomes a pile of well-organized material no one actually uses. The clearer the scenario context, the better AI knows when to search, when to follow up with a question, and when to escalate to a human.
The second move is structuring.
Material needs to be broken down into problems, judgments, rules, exceptions, evidence, and actions. Do not just feed AI an entire policy document. Give it: what problem does this rule solve, what are the boundaries of its applicability, how are exceptions handled, and where is the supporting reference?
Structuring is not for aesthetics.
It is so humans and agents can both reuse the judgment.
The third move is permissioning.
Not all knowledge should be visible to everyone, and not all knowledge should be accessible to agents. Client information, contract terms, pricing strategy, employee data, and vendor floor prices all need permission boundaries.
Permissioning is not a sign of defensiveness.
It is the prerequisite for AI to actually enter production systems.
Anthropic's official documentation for Claude Enterprise places enterprise deployment questions squarely inside governance, data control, and administrative infrastructure: organizations need to answer where data resides, who can access it, and how to audit it. Claude Enterprise also emphasizes that organizational knowledge can be connected without leaving organizational control, with access, retention, and audit governance capabilities built in.[^2]
This category of product signal makes clear that enterprise AI is no longer simply "give employees a chat interface."
The fourth move is accountability.
Knowledge expires. Rules conflict. Experience goes stale. AI cites something incorrectly. Accountability answers: who maintains it, who approves changes, who reviews it, who rolls it back, and who is responsible for errors.
Without all four moves, the knowledge base is still a document library with a better search box.
With all four, the knowledge base starts to look like organizational memory.
IV. The Knowledge Base Must Enter the Workflow
Many knowledge base projects die in one place: the system gets built, the workflow does not move.
Employees still receive tasks, get approvals, deliver work, and run retrospectives in the same places they always did. The knowledge base sits like a reference cabinet off to the side — consulted when someone has time. After AI is connected, the cabinet just gets better at answering questions.
That is not organizational memory.
Organizational memory must be embedded in the workflow.
A customer service knowledge base cannot only answer "what is the standard script?" It also needs to handle customer issue categorization, escalation rules, risk flags, review checkpoints, and the update mechanism. When a customer asks something outside the standard answer, the system needs to know when to stop improvising and when to hand off to a human.
A contract knowledge base cannot only store templates. It also needs to handle clause risk, authorization boundaries, exception approvals, and documentation trails. AI can do initial screening, but who judges high-risk clauses, who signs off, who carries accountability — those must be defined inside the workflow.
An engineering knowledge base cannot only house technical documentation. It also needs to handle design review, change logs, quality acceptance, and incident retrospectives. Otherwise a new engineer asks AI and gets an answer that looks correct but actually bypasses an organizational lesson the company learned the hard way.
Let me illustrate with a lightly anonymized scenario.
A manufacturing company had no shortage of knowledge. Product materials, after-sale records, training content, and supplier correspondence all existed. The problem: scattered across different systems, different folders, different people's machines, and various chat histories.
When frontline staff hit a problem, their first instinct was not to check the knowledge base.
It was to find a person.
Find the veteran engineer. Find the project manager. Find the colleague who "dealt with something like this before."
That tells you materials exist but organizational memory has not formed.
When we decomposed the workflows, what turned out to be valuable was not dumping all the materials into AI at once. It was identifying a few high-frequency nodes first: after-sale issue categorization, anomaly escalation, spare parts determination, customer response guidelines, quality retrospectives. For each node, three questions: who was making this call before? Where was the basis for the call? If the call was wrong, what was the impact?
Once you get to that level, the shape of the knowledge base changes.
It is no longer a large reference cabinet. It is a set of judgment cards that can be embedded into workflows.
Organizational memory is not AI getting smarter on its own.
It is the organization systematically taking the judgments that used to live in people's heads and repositioning them inside the system, node by node.
V. Organizational Memory Cannot Be Built by Extracting Employees' Experience Without Their Consent
This must be stated plainly.
The context, prompts, correction logs, and working methods employees develop through AI are not automatically company property to be mined.
Organizations genuinely need to retain experience. Without it, when an employee leaves, their knowledge leaves. When a tool changes, the memory resets. When the team grows, coordination defaults to word-of-mouth.
But organizations cannot substitute "building organizational memory" for "taking everything from employees' individual work processes."
These are two different things.
For organizational memory to be legitimate, sustainable, and legally sound, at minimum four boundaries apply.
The first is informed consent.
Employees need to know which parts of their work process will be retained, where it goes, who can see it, who can access it, and whether it will be used by agents. You cannot claim "improving efficiency" on the surface while quietly extracting all process data underneath.
The second is scenario relevance.
Not all personal experience belongs in organizational memory. Judgments tied to business outcomes, quality, safety, client relations, or compliance are the priority for retention. Personal habits, draft scraps, and private expressions should not be absorbed indiscriminately.
The third is access permissions.
Once experience enters organizational memory, define who can access it. Sales scripts, client preferences, pricing strategy, contract risk, and employee data cannot sit in the same permission layer.
The fourth is benefit alignment.
If an employee's contributed experience gets reused by the organization, what is the employee's new position? Trainer, reviewer, knowledge maintainer — or simply the person who got replaced by the system?
If you extract experience without redesigning roles and incentives, employees will quickly learn one thing: do not give away the judgment that actually matters.
That is a trust problem.
Organizational memory is not a data engineering project.
It is also a contract engineering project.
Without authorization, employees become defensive. Without permissions, systems lose control. Without benefit alignment, organizational learning burns through trust.
VI. Ten Questions for the Leader in the Room
Whether a knowledge base has become organizational memory comes down to whether it can answer ten questions.
- Which specific workflow does this knowledge serve?
- Where did this piece of knowledge come from?
- Which scenarios does it apply to?
- What are its exception conditions?
- Who can access it?
- Who is responsible for maintaining it?
- When there is a conflict, whose version takes precedence?
- Is there an audit trail for how it was accessed?
- Who rolls it back when something goes wrong?
- Has this knowledge entered real working nodes?
If the answers are not there, it is still a document library.
If the answers are there, the knowledge base is starting to look like organizational memory.
These ten questions are not designed to make the knowledge base complicated.
They are designed to prevent the organization from mistaking "more material" for "stronger organization."

Closing: After the Knowledge Base, Come Permissions, Audit, and Rollback
After a knowledge base is upgraded from a document library to organizational memory, the questions do not end — they move to the next layer.
Because once organizational memory is accessed by agents, it is no longer just "giving people better reference material." It may now influence customer responses, contract judgments, engineering decisions, after-sale actions, quality retrospectives, and even employee performance and role changes.
At that point, the organization must continue asking:
Who has the authority to let an agent access a specific piece of knowledge?
When an agent accesses something, where is the log?
Did the human adopt the recommendation or override it, and was the reasoning recorded?
When knowledge is wrong — is the fix a document revision, a workflow fix, or a permissions fix?
Can business actions already taken based on incorrect knowledge be rolled back?
These questions are what the next chapter addresses: how permissions, audit, logging, and rollback enter day-to-day operations.
The knowledge base is the material layer.
Organizational memory is the capability layer.
Permissions, audit, and rollback are the safety layer.
Connect all three layers, and agents can genuinely enter enterprise production systems. Without that connection, so-called organizational memory has just amplified the problems of the old document library.
This chapter's conclusion is simple:
A corporate knowledge base is not a document library.
It is your agents' organizational memory.
Continue reading this series:
- Series Overview: AI Adoption Is Not a Tool Purchase — It Is a Rewrite of Your Organization's Operating System
- Previous: Human-in-the-Loop Is Not a Button — It Is an Accountability Mechanism
- Next: After AI Goes In, Do You Cut Headcount?
[^1]: Sequoia Capital, "AI Ascent 2026," published May 8, 2026. https://sequoiacap.com/article/ai-ascent-2026/
[^2]: Anthropic, "Claude Enterprise," Anthropic. https://www.anthropic.com/product/enterprise